![]()
La existencia de contenido duplicado es uno de los problemas más frecuentes que se pueden encontrar cuando una página web no termina de alcanzar el posicionamiento que debería.
¿Qué es el contenido duplicado?
El contenido duplicado consiste en que los mismos contenidos aparezcan referenciados por diversas URL que pueden ser de origen interno o externo. Aunque Google no lo penaliza específicamente, si es cierto que este hecho confunde en gran medida al buscador que, al encontrar el mismo contenido en distintas direcciones, habrá de filtrar de algún modo los mismos, presentando ante la búsqueda una sola opción y descartando las demás. De esta forma, el buscador elimina de los criterios de búsquedas aquellos contenidos que identifica como copias, pudiendo ser aquellos que se encuentran en la web que se desea posicionar.
No se trata en si de una penalización, sino, más bien, de un rechazo del contenido que puede afectar de diversas formas al posicionamiento. En definitiva, se está dejando al buscador decidir entre las diversas páginas que presentan el mismo contenido cuál de ellas mostrará, pudiendo decantarse en esta decisión por la de menor peso o interés.
¿Cuáles son algunas de las causas de esta duplicación de contenidos?
Aunque son numerosos los errores o defectos que pueden conducir a esta situación, las causas más frecuentes suelen ser la canonicalización y la paginación.
Canonicalización
Este defecto se produce por algo tan sencillo como no tener en cuenta que el sitio funciona con el subdominio www.mipagina.com (con wwww) y con mipagina.com (sin www). De hecho, puede tener hasta cuatro accesos más diferentes que están dirigiendo a la misma página de inicio.
Este problema se soluciona definiendo el subdominio que se desea utilizar como principal, lo que es fácil de hacer a través de las herramientas de Google Webmaster, estableciendo un redireccionamiento al dominio deseado, o bien, añadiendo una etiqueta canónica al código de la página de origen, del tipo <link rel=”canonical” href=”http://www.site.com”/>, lo que indicará claramente al buscador que esa es la página concreta que se desea utilizar.
Paginación
Otro de los problemas frecuentes se produce cuando una página de etiquetas y categorías o, por ejemplo, una página de artículos dentro de un ecommerce, se desarrolla a través de varias páginas que, aun teniendo contenidos diferentes, confunden al buscador. En este caso se deberá indicar al buscador que todas las páginas sucesivas dependen realmente de la primera página, que es en la que debe poner toda la potencia de búsqueda, de tal forma que, en lugar de indexar cada página, solo lo haga con la primera, quedando las demás referenciadas a estas, lo que se posibilita a través de la utilización de las etiquetas rel=next y rel=prev.
¿Cómo es posible detectar la existencia de estos errores en el sitio?
Existen numerosas herramientas gratuitas en Internet que pueden ayudar a detectar el contenido duplicado, aunque ninguna de ellas suele ofrecer una solución total y será convenientte utilizar varias de ellas si se desea optimizar el seo al 100 % y no tener ningún tipo de errores en el sitio.
Una de las herramientas gratuitas más recomendables para mantener un sitio limpio de estos errores es Siteliner. Se trata de una herramienta online que presenta una información bastante completa y muy intuitiva.
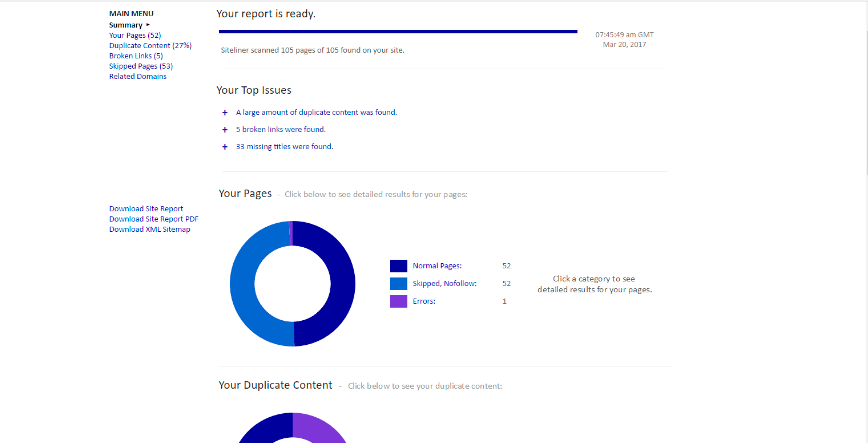
Es muy importante tener en cuenta que cuando hablamos de contenido duplicado en nuestro sitio, no nos referimos únicamente al contenido que se puede haber copiado de otros sitios y que también cuenta con otras herramientas específicas para su detección.
Sin comentarios
.jpeg "Curso marketing digital")
